Construye tu Propio Chatbot con IA: Una Guía Completa para la Implementación Local con ServBay, Python y ChromaDB (¡Sin Dependencias de Terceros!)


En una era donde la privacidad de los datos es primordial, configurar tu propio modelo de lenguaje local (LLM) proporciona una solución crucial tanto para empresas como para individuos. Este tutorial está diseñado para guiarte a través del proceso de creación de un chatbot personalizado usando ServBay, Python 3 y ChromaDB, todo alojado localmente en tu sistema. Exactamente, no necesitas descargar ningún software excepto Servbay.

Aquí están las razones clave por las que necesitas este tutorial:
Personalización Completa: Alojar tu propia aplicación de Generación Aumentada por Recuperación (RAG) localmente te otorga control total sobre su configuración y personalización. Puedes ajustar el modelo para que cumpla con tus requisitos particulares sin depender de servicios de terceros.
Privacidad Mejorada: Configurar tu modelo de lenguaje (LLM) en tus instalaciones te permite evitar los peligros de transmitir información sensible en línea. Esto es particularmente crucial para organizaciones que manejan datos privados, ya que entrenar tu modelo con recursos locales asegura que tu información permanezca segura y protegida.
Garantía de Seguridad de los Datos: Depender de modelos LLM externos puede exponer tus datos a posibles amenazas de seguridad. Al implementar tu modelo localmente, minimizas estos riesgos, manteniendo tus materiales de entrenamiento, como archivos PDF, protegidos dentro de tu propio entorno.
Control Sobre la Gestión de Datos: Operar tu propio LLM te da la libertad de manejar y procesar datos exactamente como desees. Esto abarca la incorporación de tu información propietaria en un almacén vectorial de ChromaDB, asegurando que el procesamiento de tus datos se alinee con tus estándares y criterios específicos.
Independencia de Internet: Ejecutar tu chatbot localmente significa que no dependerás de una conexión a Internet. Esto asegura un servicio consistente y acceso continuo a tu chatbot, incluso en situaciones donde estés desconectado.
Este tutorial te permitirá construir un chatbot local robusto y seguro, adaptado a tus necesidades, sin comprometer la privacidad o el control.
Generación Aumentada por Recuperación (RAG)
La Generación Aumentada por Recuperación (RAG) es una técnica avanzada que combina las fortalezas de la recuperación de información y la generación de texto para crear respuestas más precisas y contextualmente relevantes. Aquí hay un desglose de cómo funciona RAG y por qué es beneficioso:
¿Qué es RAG?
RAG es un modelo híbrido que mejora las capacidades de los modelos de lenguaje al incorporar una base de conocimiento externa o un almacén de documentos. El proceso involucra dos componentes principales:
Recuperación: En esta fase, el modelo recupera documentos o piezas de información relevantes de una fuente externa, como una base de datos o un almacén vectorial, basándose en la consulta de entrada.
Generación: La información recuperada es luego utilizada por un modelo de lenguaje generativo para producir una respuesta coherente y contextualmente apropiada.
¿Cómo Funciona RAG?
Entrada de Consulta: El usuario introduce una consulta o pregunta.
Recuperación de Documentos: El sistema usa la consulta para buscar en una base de conocimiento externa, recuperando los documentos o fragmentos de información más relevantes.
Generación de Respuesta: El modelo generativo procesa la información recuperada, integrándola con su propio conocimiento para generar una respuesta detallada y precisa.
Salida: La respuesta final, enriquecida con detalles específicos y relevantes de la base de conocimiento, se presenta al usuario.
Beneficios de RAG
Precisión Mejorada: Al aprovechar datos externos, los modelos RAG pueden proporcionar respuestas más precisas y detalladas, especialmente para consultas de dominio específico.
Relevancia Contextual: El componente de recuperación asegura que la respuesta generada esté basada en información relevante y actualizada, mejorando la calidad general de la respuesta.
Escalabilidad: Los sistemas RAG pueden escalarse fácilmente para incorporar vastas cantidades de datos, permitiéndoles manejar una amplia gama de consultas y temas.
Flexibilidad: Estos modelos pueden adaptarse a varios dominios simplemente actualizando o expandiendo la base de conocimiento externa, haciéndolos altamente versátiles.
¿Por Qué Usar RAG Localmente?
Privacidad y Seguridad: Ejecutar un modelo RAG localmente asegura que los datos sensibles permanezcan seguros y privados, ya que no necesitan ser enviados a servidores externos.
Personalización: Puedes adaptar los procesos de recuperación y generación para que se ajusten a tus necesidades específicas, incluyendo la integración de fuentes de datos propietarias.
Independencia: Una configuración local asegura que tu sistema permanezca operativo incluso sin conectividad a Internet, proporcionando un servicio consistente y confiable.

Al configurar una aplicación RAG local con herramientas como Ollama, Python y ChromaDB, puedes disfrutar de los beneficios de los modelos de lenguaje avanzados mientras mantienes el control sobre tus datos y opciones de personalización.
ServBay
ServBay es un entorno de desarrollo web local integrado, gráfico y de instalación con un solo clic, diseñado específicamente para desarrolladores web, desarrolladores de Python, desarrolladores de IA y desarrolladores de PHP. Este software es particularmente adecuado para macOS. Incluye una gama de servicios y herramientas de desarrollo web de uso común, que abarcan servidores web, bases de datos, lenguajes de programación, servidores de correo, servicios de colas y más. ServBay tiene como objetivo proporcionar a los desarrolladores un entorno de desarrollo conveniente, eficiente y unificado.
Características Principales de ServBay
Soporte para Múltiples Versiones de Python: Ejecuta múltiples versiones de Python simultáneamente para satisfacer las necesidades de diferentes proyectos.
Nombres de Dominio Personalizados y Soporte SSL: Configura fácilmente nombres de dominio locales y certificados SSL para simular entornos de producción reales.
Operaciones Rápidas: Admite el inicio en el arranque, acceso rápido a través de la barra de menú y gestión de línea de comandos para mejorar la eficiencia del desarrollo.
Gestión de Servicios Unificada: Integra Python, PHP, Node.js y Ollama, facilitando la gestión de múltiples servicios de desarrollo.
Entorno de Sistema Limpio: Evita la contaminación del sistema ejecutando todos los servicios en entornos aislados.
Penetración y Compartición en la Intranet: Admite la penetración en la intranet para sitios web locales, facilitando la compartición de resultados de desarrollo con los miembros del equipo.
Guía de Instalación de ServBay
Requisitos: macOS 12.0 Monterey o posterior
Descarga la Última Versión de ServBay
Instalación:
Haz doble clic en el archivo .dmg descargado para abrirlo.
En la ventana que se abre, arrastra el icono de ServBay.app a la carpeta Aplicaciones.

Cuando uses ServBay por primera vez, se requiere inicialización. Generalmente, puedes seleccionar la instalación predeterminada, u opcionalmente seleccionar Ollama para soporte de programación de IA.

Una vez completada la instalación, abre ServBay.

Introduce tu contraseña. Después de que la instalación esté completa, puedes encontrar ServBay en el directorio de Aplicaciones.
Accede a la interfaz principal.

Además de Python, ServBay también proporciona un sólido soporte para PHP y Node.js, cubriendo una amplia gama de versiones desde PHP 5.6 hasta PHP 8.5 y Node.js 12 hasta Node.js 23.
Una de las características clave de ServBay es la capacidad de cambiar rápidamente entre diferentes versiones de software. Esta flexibilidad es esencial para los desarrolladores que necesitan probar e implementar aplicaciones en diversos entornos.

Instalación con un solo clic de todas las versiones de Python.

Instalación con un solo clic de todos los modelos de Ollama
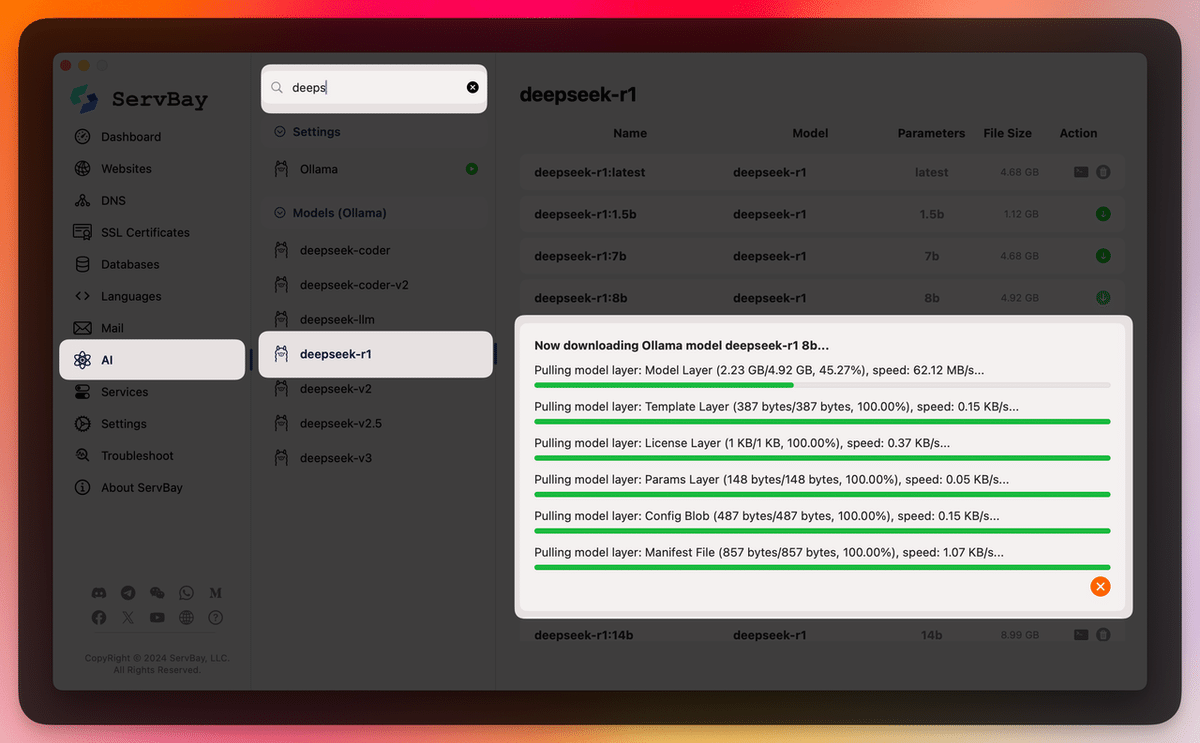
Requisitos Previos
Antes de sumergirte en la configuración, asegúrate de tener los siguientes requisitos previos:
Python 3: Python es un lenguaje de programación versátil que usarás para escribir el código de tu aplicación RAG.
ChromaDB: Una base de datos vectorial que almacenará y gestionará las incrustaciones de nuestros datos.
Servbay: Para descargar y servir LLMs personalizados en nuestra máquina local.
Paso 1: Instala Python 3 y configura tu entorno
Para instalar y configurar nuestro entorno de Python 3, sigue estos pasos: Haz clic en el botón de Python de Servbay y luego selecciona una versión de Python. Luego, asegúrate de que Python 3 esté instalado y se ejecute correctamente:
$ python3 --version # Python 3.12.9
Crea una carpeta para tu proyecto. Por ejemplo, local-rag:
$ mkdir local-rag
$ cd local-rag
Crea un entorno virtual llamado venv:
$ python3 -m venv venv
Activa el entorno virtual:
$ source venv/bin/activate
# Windows
# venv\Scripts\activate
Paso 2: Instala ChromaDB y otras dependencias
Instala ChromaDB usando pip:
$ pip install --q chromadb
Instala las herramientas de Langchain para trabajar sin problemas con tu modelo:
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"
Instala Flask para servir tu aplicación como un servicio HTTP:
$ pip install --q flask
Paso 3: Instala Ollama
Para instalar Ollama, sigue estos pasos. Haz clic en el botón AI de servbay y luego selecciona un modelo que desees.
Construye la aplicación RAG
Ahora que has configurado tu entorno con Python, Ollama, ChromaDB y otras dependencias, es hora de construir tu aplicación RAG local personalizada. En esta sección, repasaremos el código práctico de Python y proporcionaremos una descripción general de cómo estructurar tu aplicación.
app.py
Este es el archivo principal de la aplicación Flask. Define rutas para incrustar archivos en la base de datos vectorial y recuperar la respuesta del modelo.
import os
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
# Establecer carpeta temporal
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)
embed.py
Este módulo maneja el proceso de incrustación, incluyendo guardar archivos cargados, cargar y dividir datos, y agregar documentos a la base de datos vectorial.
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Función para verificar si el archivo cargado está permitido (solo archivos PDF)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Función para guardar el archivo cargado en la carpeta temporal
def save_file(file):
# Guardar el archivo cargado con un nombre de archivo seguro y devolver la ruta del archivo
timestamp = datetime.now().timestamp()
filename = f"{timestamp}_{secure_filename(file.filename)}"
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Función para cargar y dividir los datos del archivo PDF
def load_and_split_data(file_path):
# Cargar el archivo PDF y dividir los datos en fragmentos
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Función principal para manejar el proceso de incrustación
def embed(file):
# Verificar si el archivo es válido, guardarlo, cargar y dividir los datos, agregar a la base de datos y eliminar el archivo temporal
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False
query.py
Este módulo procesa las consultas de los usuarios generando múltiples versiones de la consulta, recuperando documentos relevantes y proporcionando respuestas basadas en el contexto.
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'deepseek-r1:1.5b')
# Función para obtener las plantillas de prompt para generar preguntas alternativas y responder basándose en el contexto
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""Eres un asistente de modelo de lenguaje de IA. Tu tarea es generar cinco
versiones diferentes de la pregunta del usuario dada para recuperar documentos relevantes de
una base de datos vectorial. Al generar múltiples perspectivas sobre la pregunta del usuario, tu
objetivo es ayudar al usuario a superar algunas de las limitaciones de la búsqueda de similitud basada en la distancia.
Proporciona estas preguntas alternativas separadas por saltos de línea.
Pregunta original: {question}"""
)
template = """Responde la pregunta basándote ÚNICAMENTE en el siguiente contexto:
{context}
Pregunta: {question}"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Función principal para manejar el proceso de consulta
def query(input):
if input:
# Inicializar el modelo de lenguaje con el nombre de modelo especificado
llm = ChatOllama(model=LLM_MODEL)
# Obtener la instancia de la base de datos vectorial
db = get_vector_db()
# Obtener las plantillas de prompt
QUERY_PROMPT, prompt = get_prompt()
# Configurar el recuperador para generar múltiples consultas usando el modelo de lenguaje y el prompt de consulta
retriever = MultiQueryRetriever.from_llm(db.as_retriever(), llm, prompt=QUERY_PROMPT)
# Definir la cadena de procesamiento para recuperar el contexto, generar la respuesta y analizar la salida
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
response = chain.invoke(input)
return response
return None
get_vector_db.py
Este módulo inicializa y devuelve la instancia de la base de datos vectorial utilizada para almacenar y recuperar incrustaciones de documentos.
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
# Crear una instancia del modelo de incrustación
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL, show_progress=True)
# Inicializar el almacén vectorial Chroma con los parámetros especificados
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db
¡Ejecuta tu aplicación!
Crea un archivo .env para almacenar tus variables de entorno:
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'
Ejecuta el archivo app.py para iniciar el servidor de tu aplicación:
$ python3 app.py
Una vez que el servidor esté funcionando, puedes comenzar a realizar solicitudes a los siguientes puntos finales:
Comando de ejemplo para incrustar un archivo PDF (por ejemplo, resume.pdf):
#!/bin/bash
curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/liyinan/Documents/works/matrix_multi.pdf # Reemplaza con la ruta de tu archivo
Respuesta:
{
"message": "File embedded successfully"
}
Comando de ejemplo para hacer una pregunta a tu modelo:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "¿Quién es Nasser?" }'
# Respuesta
{
"message": "Nasser Maronie es un desarrollador Full Stack con experiencia en desarrollo de aplicaciones web y móviles. Ha trabajado como Lead Full Stack Engineer en Ulventech, Senior Full Stack Engineer en Speedoc, Senior Frontend Engineer en Irvins y Software Engineer en Tokopedia. Sus stacks tecnológicos incluyen Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase y Supabase. Tiene una licenciatura en Sistemas de Información de la Universidad Amikom Yogyakarta."
}
Conclusión
Siguiendo estas instrucciones, puedes ejecutar e interactuar eficazmente con tu aplicación RAG local personalizada usando Python, Ollama y ChromaDB, adaptada a tus necesidades. Ajusta y expande la funcionalidad según sea necesario para mejorar las capacidades de tu aplicación.
Al aprovechar las capacidades de la implementación local, no solo proteges la información sensible, sino que también optimizas el rendimiento y la capacidad de respuesta. Ya sea que estés mejorando las interacciones con los clientes o simplificando los procesos internos, una aplicación RAG implementada localmente ofrece flexibilidad y robustez para adaptarse y crecer con tus requerimientos.
Crea un entorno virtual llamado venv:
$ python3 -m venv venv
Activa el entorno virtual:
$ source venv/bin/activate
# Windows
# venv\Scripts\activate
Paso 2: Instala ChromaDB y otras dependencias
Instala ChromaDB usando pip:
$ pip install --q chromadb
Instala las herramientas de Langchain para trabajar sin problemas con tu modelo:
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"
Instala Flask para servir tu aplicación como un servicio HTTP:
$ pip install --q flask
Paso 3: Instala Ollama
Para instalar Ollama, sigue estos pasos: Haz clic en el botón AI de Servbay y luego selecciona el modelo que prefieras.
Construye la aplicación RAG
Ahora que has configurado tu entorno con Python, Ollama, ChromaDB y otras dependencias, es hora de construir tu aplicación RAG local personalizada. En esta sección, repasaremos el código Python práctico y proporcionaremos una descripción general de cómo estructurar tu aplicación.
app.py
Este es el archivo principal de la aplicación Flask. Define las rutas para incrustar archivos en la base de datos vectorial y recuperar la respuesta del modelo.
import os
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
# Establecer carpeta temporal
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)
embed.py
Este módulo maneja el proceso de incrustación, incluyendo guardar los archivos subidos, cargar y dividir los datos, y añadir documentos a la base de datos vectorial.
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Función para verificar si el archivo subido está permitido (solo archivos PDF)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Función para guardar el archivo subido en la carpeta temporal
def save_file(file):
# Guarda el archivo subido con un nombre de archivo seguro y devuelve la ruta del archivo
timestamp = datetime.now().timestamp()
filename = f"{timestamp}_{secure_filename(file.filename)}"
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Función para cargar y dividir los datos del archivo PDF
def load_and_split_data(file_path):
# Carga el archivo PDF y divide los datos en fragmentos
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Función principal para manejar el proceso de incrustación
def embed(file):
# Verifica si el archivo es válido, guárdalo, carga y divide los datos,
# agrégalo a la base de datos y elimina el archivo temporal
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False
query.py
Este módulo procesa las consultas de los usuarios generando múltiples versiones de la consulta, recuperando documentos relevantes y proporcionando respuestas basadas en el contexto.
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'deepseek-r1:1.5b')
# Función para obtener las plantillas de prompt para generar preguntas alternativas y responder según el contexto
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from
a vector database. By generating multiple perspectives on the user question, your
goal is to help the user overcome some of the limitations of the distance-based
similarity search. Provide these alternative questions separated by newlines.
Original question: {question}"""
)
template = """Answer the question based ONLY on the following context:
{context}
Question: {question}"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Función principal para manejar el proceso de consulta
def query(input):
if input:
# Inicializa el modelo de lenguaje con el nombre del modelo especificado
llm = ChatOllama(model=LLM_MODEL)
# Obtiene la instancia de la base de datos vectorial
db = get_vector_db()
# Obtiene las plantillas de prompt
QUERY_PROMPT, prompt = get_prompt()
# Configura el recuperador para generar múltiples consultas utilizando el modelo de lenguaje y el prompt de consulta
retriever = MultiQueryRetriever.from_llm(db.as_retriever(), llm, prompt=QUERY_PROMPT)
# Define la cadena de procesamiento para recuperar el contexto, generar la respuesta y analizar la salida
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
response = chain.invoke(input)
return response
return None
get_vector_db.py
Este módulo inicializa y devuelve la instancia de la base de datos vectorial utilizada para almacenar y recuperar incrustaciones de documentos.
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text')
def get_vector_db():
# Crea una instancia del modelo de incrustación
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL, show_progress=True)
# Inicializa el almacén vectorial Chroma con los parámetros especificados
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db
¡Ejecuta tu aplicación!
Crea un archivo .env para almacenar tus variables de entorno:
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral'
TEXT_EMBEDDING_MODEL = 'nomic-embed-text'
Ejecuta el archivo app.py para iniciar el servidor de tu aplicación:
$ python3 app.py
Una vez que el servidor se esté ejecutando, puedes comenzar a realizar solicitudes a los siguientes puntos finales:
Comando de ejemplo para incrustar un archivo PDF (por ejemplo, resume.pdf):
#!/bin/bash
curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/liyinan/Documents/works/matrix_multi.pdf
Respuesta:
{
"message": "File embedded successfully"
}
Comando de ejemplo para hacer una pregunta a tu modelo:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Who is Nasser?" }'
# Respuesta
{
"message": "Nasser Maronie is a Full Stack Developer with experience in web and mobile app development. He has worked as a Lead Full Stack Engineer at Ulventech, a Senior Full Stack Engineer at Speedoc, a Senior Frontend Engineer at Irvins, and a Software Engineer at Tokopedia. His tech stacks include Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase, and Supabase. He has a Bachelor's degree in Information System from Universitas Amikom Yogyakarta."
}
Conclusión
Siguiendo estas instrucciones, puedes ejecutar e interactuar eficazmente con tu aplicación RAG local personalizada utilizando Python, Ollama y ChromaDB, adaptada a tus necesidades. Ajusta y expande la funcionalidad según sea necesario para mejorar las capacidades de tu aplicación.
Al aprovechar las capacidades de la implementación local, no solo proteges la información confidencial, sino que también optimizas el rendimiento y la capacidad de respuesta. Ya sea que estés mejorando las interacciones con los clientes o simplificando los procesos internos, una aplicación RAG implementada localmente ofrece flexibilidad y solidez para adaptarse y crecer con tus requisitos.